

Optimization of job shop scheduling problem based on deep reinforcement learning
-
摘要: 针对作业车间调度问题求解的复杂性,以最小化最大完工时间为目标,提出基于深度强化学习优化算法求解作业车间调度问题。首先,基于析取图模型构建深度强化学习的调度环境,并建立三通道状态特征,设计20种复合启发式调度规则作为动作空间,将奖励函数等价为机器利用率;利用深度卷积神经网络搭建动作网络和目标网络,以状态作为输入,输出每个动作的Q值,进而使用行动有效性探索和利用策略选取动作;最后,计算即时奖励和更新调度环境。使用标准案例验证了算法可以平衡求解质量和时间,训练好的智能体对非零初始状态下调度问题具有很好的泛化性。Abstract: Aiming at the optimization problem of minimizing the maximum completion time in job shop scheduling, a deep reinforcement learning optimization algorithm is proposed. First, a deep reinforcement learning scheduling environment is built based on the disjunctive graph model, and three channels of state characteristics are established. The action space consists of 20 designed combination scheduling rules. The reward function is designed based on the proportional relationship between the total work of the scheduled operation and the current maximum completion time. The deep convolutional neural network is used to construct action network and target network, and the state features are used as inputs to output the Q value of each action. Then, the action is selected by using the action validity exploration and exploitation strategy. Finally, the immediate reward is calculated and the scheduling environment is updated. Experiments are carried out using benchmark instances to verify the algorithm. The results show that it can balance solution quality and computation time effectively, and the trained agent has good generalization ability to the scheduling problem in the non-zero initial state.
-
Key words:
- deep reinforcement learning /
- job shop scheduling /
- scheduling rules
-
表 2 启发式调度规则
No. 特性 Rule 描述 1 全局 SPT 选择工序加工时间最短的工件 2 LPT 选择工序加工时间最长的工件 3 SPT*TWK 选择工序加工时间与总加工时间乘积最小的工件 4 LPT*TWK 选择工序加工时间与总加工时间乘积最大的工件 5 SPT/TWK 选择工序加工时间与总加工时间之比最小的工件 6 LPT/TWK 选择工序加工时间与总加工时间之比最大的工件 7 SPT*TWKR 选择工序加工时间与剩余加工时间乘积最小的工件 8 LPT*TWKR 选择工序加工时间与剩余加工时间乘积最大的工件 9 SPT/TWKR 选择工序加工时间与剩余加工时间之比最小的工件 10 LPT/TWKR 选择工序加工时间与剩余加工时间之比最大的工件 11 局部 SRM 选择除当前考虑工序外剩余加工时间最短的工件 12 LRM 选择除当前考虑工序外剩余加工时间最长的工件 13 SRPT 选择剩余加工时间最短的工件 14 LRPT 选择剩余加工时间最长的工件 15 SSO 选择下一工序加工时间最短的
工件16 LSO 选择下一工序加工时间最长的
工件17 SPT+SSO 选择当前工序加工时间与后续工序加工时间最短的工件 18 LPT+LSO 选择当前工序加工时间与后续工序加工时间最长的工件 19 SQN 选择等待时间最短的工件 20 LQN 选择等待时间最长的工件  下载: 导出CSV
下载: 导出CSV
表 3 行动有效性探索和利用策略的动作选择流程
Input: 环境$ {\rm{{E}_{t}}} $ Output: 状态$ {\rm{{s}_{t},{s}_{t+1}}} $,动作${\rm{{a}_{t}}}$,奖励${\rm{ {r}_{t} }}$,环境$ {\rm{{E}_{t}}} $ 1: 从$ {\rm{{E}_{t}}} $随机选择一台空闲机器$ {\rm{{M}_{k}}} $,建立允许在机器${\rm{ {M}_{k}}} $上加工的工件集合$ {\rm{{O}_{k} }}$ 2: $ {\rm{{s}_{t}}}\leftarrow {\rm{{E}_{t}}} $ 3: 取随机数P服从[0,1]的均匀分布 4: if $ \left|{\rm{{O}_{k}}}\right| $=1 5: 直接安排工序在机器$ {\rm{{M}_{k}}} $上加工,$ {\rm{{a}_{t}}}=-1 $ 6: else if $\mathrm{{\rm{P}}} < {\text{ε}}$ 7: 从动作集合A随机选择一个动作$ {a}_{t} $ 8: Else 9: $\underset{ { {\rm{a} }'} }{ { {\rm{a} } }_{ {\rm{t} } }={\rm{argmax}}}{\rm{Q} }\left({\rm{ {s}_{t} } },{\rm{a} };{\text{θ} } \right)$ 10: end if 11: 执行动作$ {\rm{{a}_{t}}} $ 12: end if 13: 更新环境$ {\rm{{E}_{t}}} $,$ {{\rm{s}}}_{{\rm{t}}+1},{\rm{{r}_{t}}}\leftarrow {\rm{{E}_{t}}} $ 14: return $ {\rm{{s}_{t},{s}_{t+1},{r}_{t},{a}_{t},{E}_{t}}} $
下载: 导出CSV
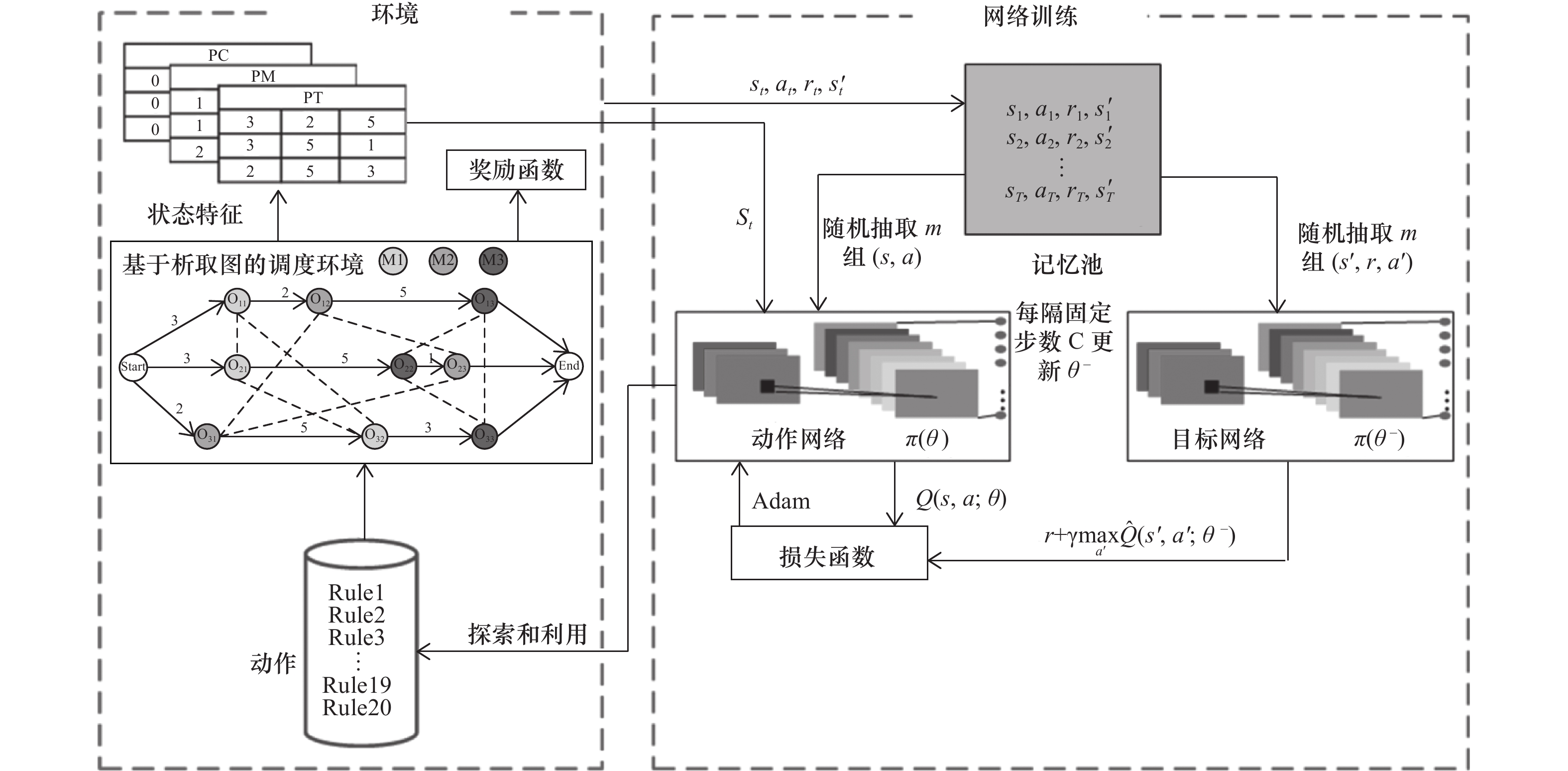
表 4 基于DRL的作业车间调度优化算法流程
1: 初始化记忆池D容量为B 2: 用随机权重$ {\text{θ}} $初始化动作网络$ \mathrm{Q} $ 3: 初始化目标网络$ \widehat{\rm{Q}}\mathrm{权}\mathrm{重} {\text{θ}} ^{-}= {\text{θ}} $ 4: for e=1, 2, ···, E do 5: 初始化调度环境$ {\rm{E}}_{0},{\rm{s}}_{0} $ 6: $ \rm{T}\leftarrow 0 $ 7: While 所有工序是否加工完毕 do 8: $ \rm{M}\rm{s}\leftarrow {\rm{{E}_{t}}} $ 9: if $ \left|\mathrm{M}\mathrm{s}\right|\ne 0 $ 10: 使用表3获得$ {\rm{{s}_{t},{s}_{t+1},{r}_{t},{a}_{t},{E}_{t}}} $ 11: if $ {\rm{{a}_{t}}}\ne -1 $ 12: 将$ {\rm{{s}_{t} }}$,$ {\rm{{a}_{t} }}$,${\rm{ {r}_{t} }}$,$ {\rm{{s}_{t+1} }}$存储在记忆池D中,$ {\rm{b}}={\rm{b}}+1 $ 13: if b>B 14: 从$ D $中随机抽取一批样本($ {\rm{{s}_{j},{a}_{j},{r}_{j},{s}_{j+1} }}$) 15: $ {\rm{{y}_{k}}}=\left\{\begin{array}{l}{\rm{{r}_{j}}}, 如果j+1步完成调度\\ {\rm{{r}_{j}}}+\text{γ} \underset{{\rm{{a}_{j}}}}{{\rm{max}}} \widehat{\mathrm{Q}}\left(\left({{\rm{s}}}_{{\rm{j}}+1}\right),{\rm{{a}_{j}}};{\text{θ}}_{{\rm{k}}}^{-}\right), 其他\end{array}\right. $ 16: $ \mathrm{计}\mathrm{算}\Delta \mathrm{{\text{θ}} }=\mathrm{\text{α}}{({\rm{{y}_{k}}}-{\rm{Q}}({\rm{{s}_{j},{a}_{j}}};{{\text{θ}} }_{{\rm{k}}}))}^{2}{\nabla }_{{{\text{θ}} }_{{\rm{k}}}}{\rm{Q}}\left({\rm{{s}_{j},{a}_{j}}};{{\text{θ}} }_{{\rm{k}}}\right) $的梯度下降,更新动作值 17: 动作网络$ \mathrm{Q} $参数更新$ {\text{θ}} ={\text{θ}} +\Delta {\text{θ}} $ 18: 每隔$ {\rm{C}} $步更新一次目标网络$ \widehat{\mathrm{Q}} $参数$ {{\text{θ}} }^{-}={\text{θ}} $ 19: end if 20: end if 21: else if 22: 更新T为当前状态下工序的最小完工时间,更新调度环境$ {\rm{{E}_{t}}} $ 23: end if 24: end while 25: end for
下载: 导出CSV
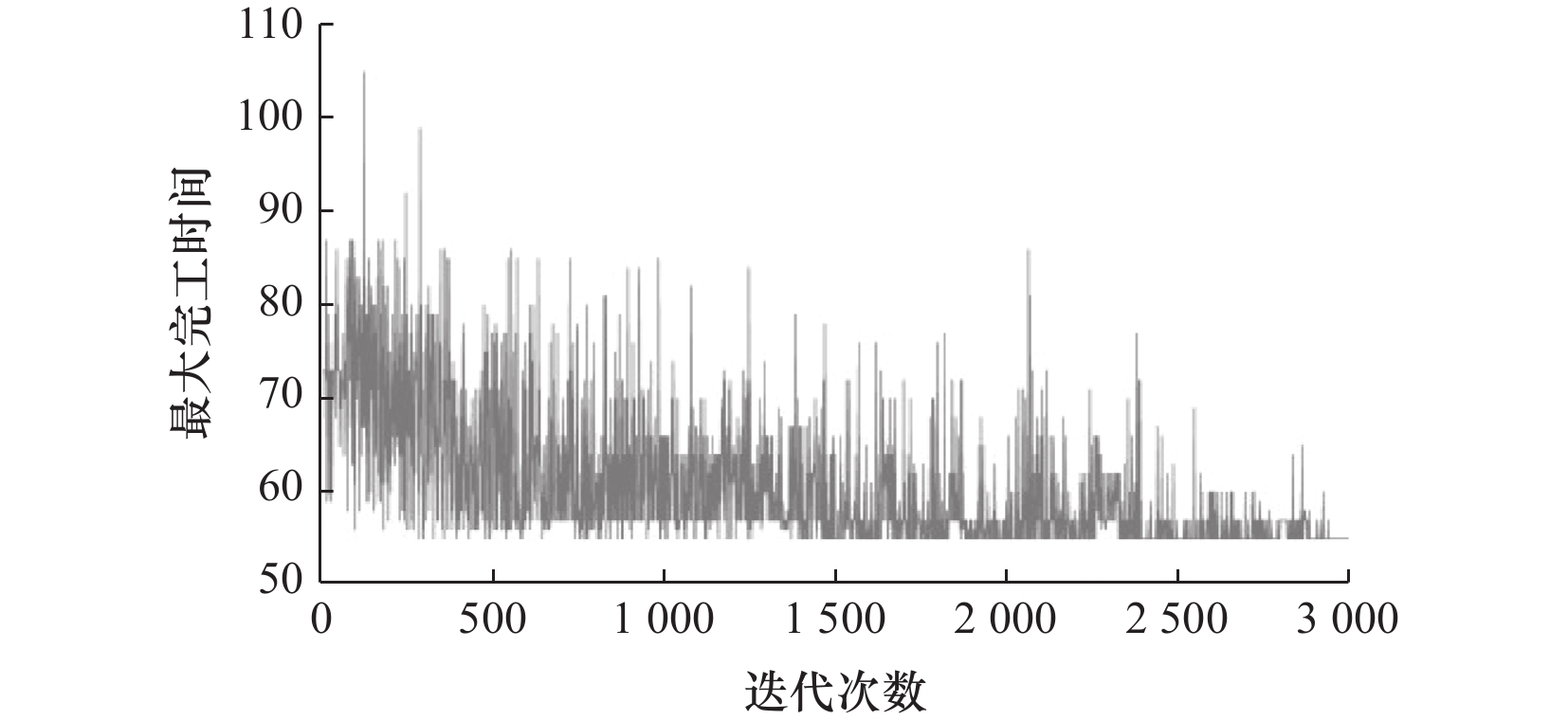
表 5 参数设置
参数名称 参数值 迭代次数 3 000 经验池大小 10 000 随机梯度下降采样样本大小 128 学习率 0.001 目标网络的更新频率 200 $ \varepsilon $的初始值 0.1 $ \varepsilon $最终值 0
下载: 导出CSV
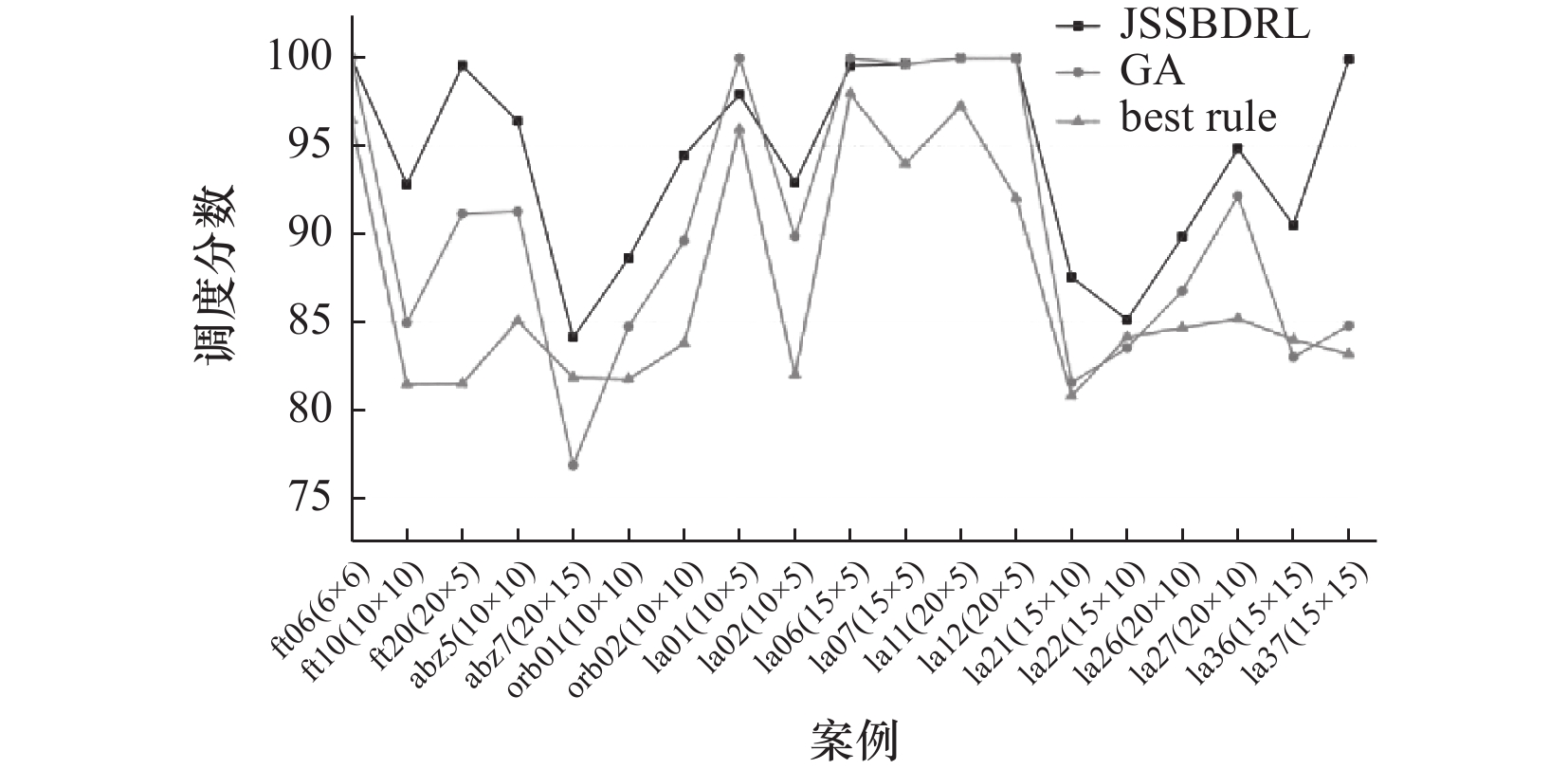
表 6 实验结果对比
案例 LU UB best rule GA JSSBDRL ft06(6x6) 55 55 57 55 55 ft10(10x10) 930 930 1 142 1 095 1 002 ft20(20x5) 1 165 1 165 1 430 1 278 1 170 abz5(10x10) 1 234 1 234 1 451 1 352 1 280 abz7(20x15) 656 656 802 854 780 orb01(10x10) 1 059 1 059 1 296 1 250 1 195 orb02(10x10) 888 888 1 060 991 940 la01(10x5) 666 666 694 666 680 la02(10x5) 655 655 799 729 705 la06(15x5) 926 926 945 926 930 la07(15x5) 890 890 947 893 893 la11(20x5) 1 222 1 222 1 256 1 222 1 222 la12(20x5) 1 039 1 039 1 129 1 039 1 039 la21(15x10) 1 046 1 046 1 295 1 283 1 195 la22(15x10) 927 927 1 102 1 110 1 089 la26(20x10) 1 218 1 218 1 439 1 404 1 356 la27(20x10) 1 235 1 235 1 450 1 340 1 302 la36(15x15) 1 268 1 268 1 510 1 528 1 401 la37(15x15) 1 397 1 397 1 680 1 648 1 398
下载: 导出CSV
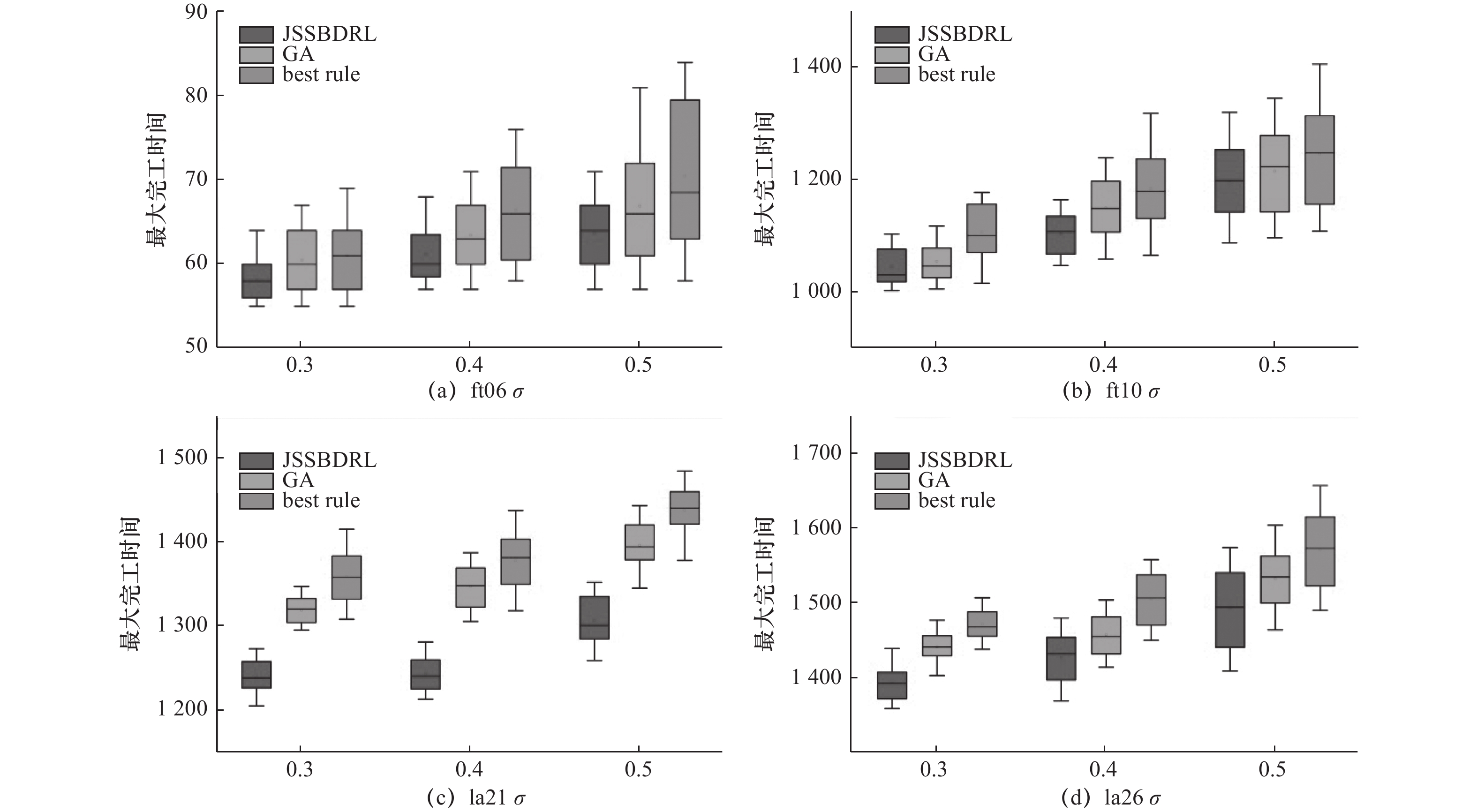
表 7 不同调度比下测试时间对比
案例 $ \sigma $ JSSBDRL/s best rule/s GA/s ft06(6$ \times $6) 0.3 1.00 0.028 1.20 0.4 0.95 0.022 1.14 0.5 0.90 0.016 1.08 ft10(10$ \times $10) 0.3 1.10 0.072 2.24 0.4 1.00 0.066 2.14 0.5 0.90 0.060 2.04 la21(15$ \times $10) 0.3 1.20 0.142 4.00 0.4 1.05 0.132 3.86 0.5 0.95 0.122 3.72 la26(20$ \times $10) 0.3 1.36 0.198 5.60 0.4 1.18 0.182 5.44 0.5 1.00 0.166 5.28
下载: 导出CSV
-
[1] Meeran S, Morshed M S. A hybrid genetic tabu search algorithm for solving job shop scheduling problems: a case study[J]. Journal of Intelligent Manufacturing, 2011, 23(4): 1063-1078. [2] Ahmadian M M, Khatami M, Salehipour A, et al. Four decades of research on the open-shop scheduling problem to minimize the makespan[J]. European Journal of Operational Research, 2021, 295(2): 399-426. doi: 10.1016/j.ejor.2021.03.026 [3] 王艳红, 赵也践, 刘文鑫. 数据挖掘算法在作业车间调度问题中的应用 [J/OL]. 计算机集成制造系统, https://kns.cnki.net/kcms/detail/11.5946.TP.20211214.1816.004.html. [4] 王成龙, 李诚, 冯毅萍, 等. 作业车间调度规则的挖掘方法研究[J]. 浙江大学学报:工学版, 2015, 49(3): 421-429,438. [5] Fuendeling C U, Trautmann N. A priority-rule method for project scheduling with work-content constraints[J]. European Journal of Operational Research, 2010, 203(3): 568-574. doi: 10.1016/j.ejor.2009.09.019 [6] 范华丽, 熊禾根, 蒋国璋, 等. 动态车间作业调度问题中调度规则算法研究综述[J]. 计算机应用研究, 2016, 33(3): 648-653. doi: 10.3969/j.issn.1001-3695.2016.03.002 [7] Durasevic M, Jakobovic D. A survey of dispatching rules for the dynamic unrelated machines environment[J]. Expert Systems with Application, 2018, 113: 555-569. doi: 10.1016/j.eswa.2018.06.053 [8] 郑倩, 奚立峰. 飞机移动生产线作业调度问题的启发式算法[J]. 工业工程与管理, 2015, 20(2): 116-121. doi: 10.3969/j.issn.1007-5429.2015.02.018 [9] Mouelhi-Chibani W, Pierreval H. Training a neural network to select dispatching rules in real time[J]. Computers & Industrial Engineering, 2010, 58(2): 249-256. [10] Vinyals O, Babuschkin I, Czarnecki W M, et al. Grandmaster level in StarCraft II using multi-agent reinforcement learning[J]. Nature, 2019, 575(7782): 350-354. doi: 10.1038/s41586-019-1724-z [11] Wang Q, Tang C. Deep reinforcement learning for transportation network combinatorial optimization: a survey[J]. Knowledge-Based Systems, 2021, 233: 1-22. [12] Guo W, Tian W, Ye Y, et al. Cloud resource scheduling with deep reinforcement learning and imitation learning[J]. IEEE Internet of Things Journal, 2021, 8(5): 3576-3586. doi: 10.1109/JIOT.2020.3025015 [13] Zhao Y, Zhang H. Application of machine learning and rule scheduling in a job-shop production control system[J]. International Journal of Simulation Modelling, 2021, 20(2): 410-421. doi: 10.2507/IJSIMM20-2-CO10 [14] 王凌, 潘子肖. 基于深度强化学习与迭代贪婪的流水车间调度优化[J]. 控制与决策, 2021, 36(11): 2609-2617. doi: 10.13195/j.kzyjc.2020.0608 [15] 肖鹏飞, 张超勇, 孟磊磊, 等. 基于深度强化学习的非置换流水车间调度问题[J]. 计算机集成制造系统, 2021, 27(1): 192-205. doi: 10.13196/j.cims.2021.01.018 [16] Luo S. Dynamic scheduling for flexible job shop with new job insertions by deep reinforcement learning[J]. Applied Soft Computing, 2020, 91: 1-44. [17] Christiano P F, Leike J, Brown T, et al. Deep reinforcement learning from human preferences[J]. Advances in Neural Information Processing Systems, 2017, 30: 1-10. [18] Miller T, Niu J. An assessment of strategies for choosing between competitive marketplaces[J]. Electronic Commerce Research and Applications, 2012, 11(1): 14-23. doi: 10.1016/j.elerap.2011.07.009 [19] Han B A, Yang J J. Research on adaptive job shop scheduling problems based on dueling double DQN[J]. IEEE Access, 2020, 8: 186474-186495. doi: 10.1109/ACCESS.2020.3029868 -
 下载:
下载:

 点击查看大图
点击查看大图

图(6) / 表(7)
计量
- 文章访问数: 154
- HTML全文浏览量: 32
- PDF下载量: 28
- 被引次数: 0


